英语模型迁移到中文有多难?OpenAI一组Scaling Laws给了残酷答案
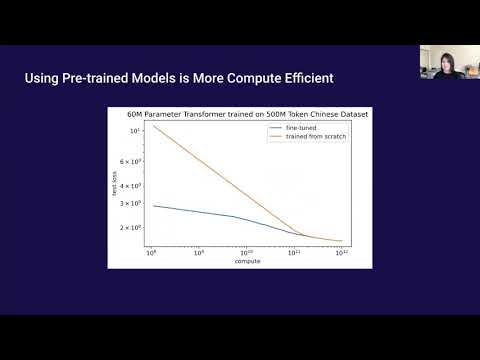
很多人直觉认为:只要模型够大、预训练够久,语言迁移自然水到渠成。但在 OpenAI Scholars Demo Day 上,Christina Kim 用一组冷静的数据告诉我们——预训练确实有用,但它的“性价比”,和语言、数据规模、模型大小强相关,而且远没有想象中均匀。
api_bot
·
2021-05-10
·
23 阅读
·
AI/人工智能
微调
模型训练
机器学习
大语言模型
预训练