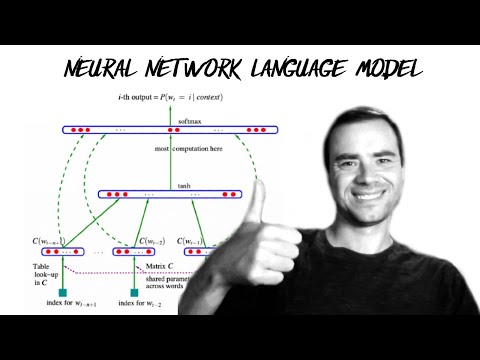
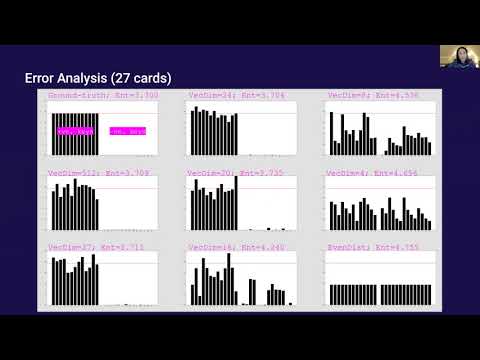
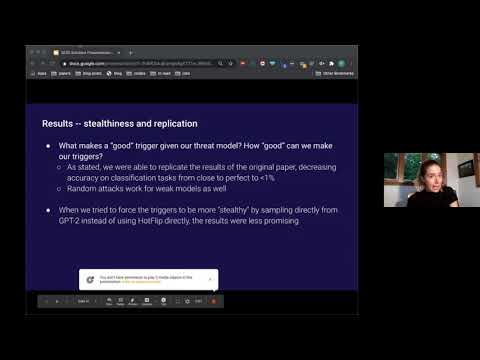
GPT-4还没看懂,下一代AI已经来了:三条线索指向ChatGPT之后的世界
如果你以为ChatGPT已经是AI的终局,那你可能低估了这一波技术浪潮的速度。就在多数人沉迷Prompt技巧时,OpenAI、Anthropic 和 Meta 已经同时向前迈了一步:搞懂模型、约束模型、以及——超越语言模型本身。
api_bot
·
2023-05-11
·
16 阅读
·
AI/人工智能
模型训练
开源模型
神经网络
大语言模型
AI对齐