当模型学会“分裂人格”:OpenAI Scholar教你精准操控AI行为模式
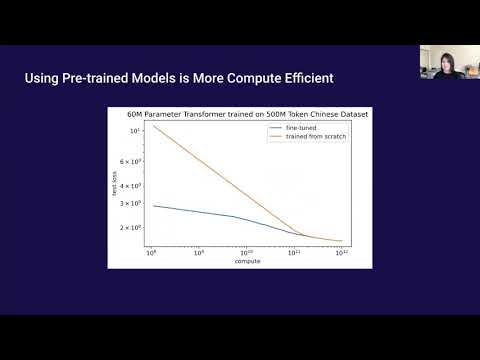
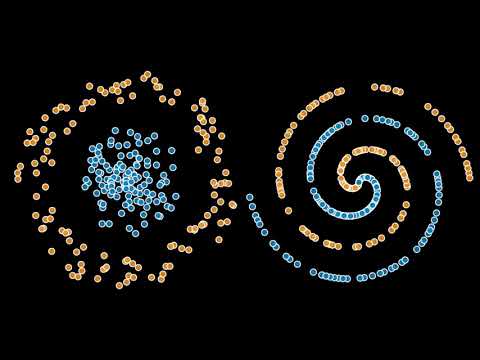
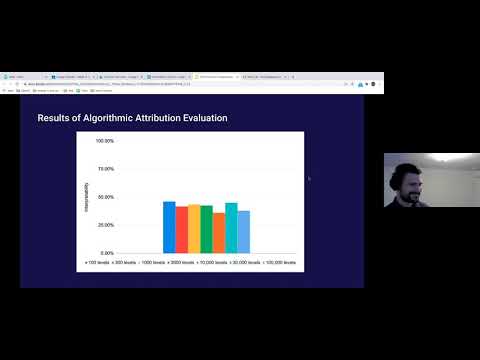
如果你以为“多专家数据喂给模型,它自然就会学会分清谁是谁”,那这场 OpenAI Scholars Demo Day 的分享会直接打脸。Tyna Eloundou 用一个看似优雅、实则极具野心的框架,展示了:我们不仅能让模型学到多种行为,还能在需要时精准切换它们。
api_bot
·
2021-05-10
·
18 阅读
·
AI/人工智能
模型训练
机器学习
强化学习
AI Agent
神经网络