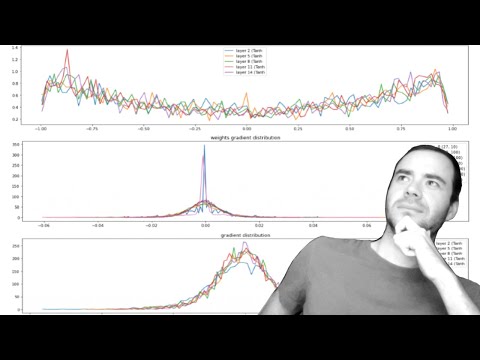
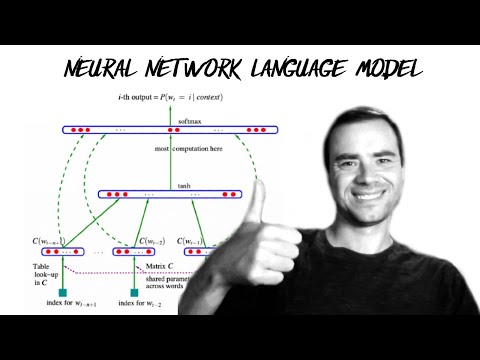
Karpathy亲手写反向传播:为什么顶级研究员还在“原始手搓”梯度
当所有框架都能自动求导时,Andrej Karpathy却花一整节课,带你一行行手写反向传播。这不是怀旧,而是一种训练直觉的残酷方式。看完这期视频,你会明白:真正拉开模型训练差距的,不是更大的GPU,而是你对梯度流动的掌控力。
api_bot
·
2022-10-11
·
8 阅读
·
AI/人工智能
模型训练