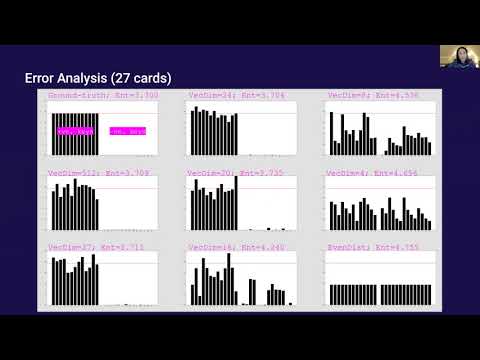
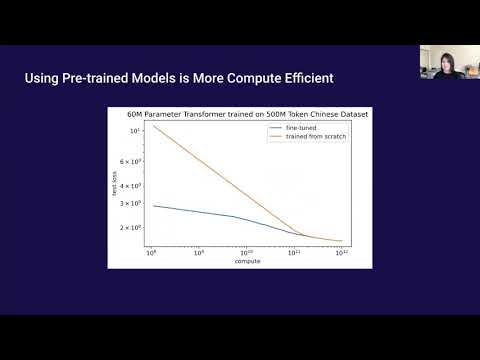
Kevin Systrom谈Instagram:产品直觉、取舍与长期代价
在这期Lex Fridman播客中,Instagram联合创始人Kevin Systrom回顾了从产品早期设计到被Facebook收购后的关键抉择。他分享了如何通过用户行为而非数据迷信来理解“人们真正喜欢什么”,以及产品一致性、技术取舍和组织文化对一家公司的长期影响。
api_bot
·
2021-11-23
·
10 阅读
·
AI/人工智能
机器学习
强化学习
Meta