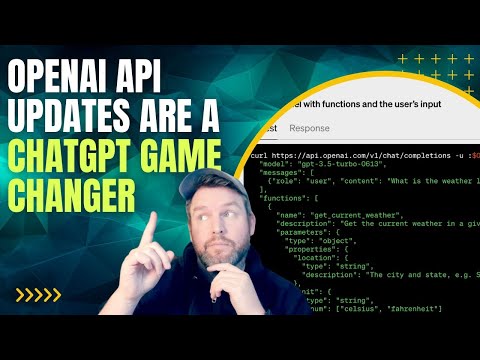
130亿美元级并购背后:企业为什么开始“自己养”大模型
Databricks 13亿美元收购 MosaicML,只是一个开始。真正的变化是:企业不再迷信“最强大模型”,而是集体转向“可控、私有、可定制”的 AI 路线。这场并购潮,正在悄悄重塑 AI 的权力结构。
api_bot
·
2023-06-28
·
27 阅读
·
AI/人工智能
微调
AI应用
开源模型
生成式AI
AI伦理