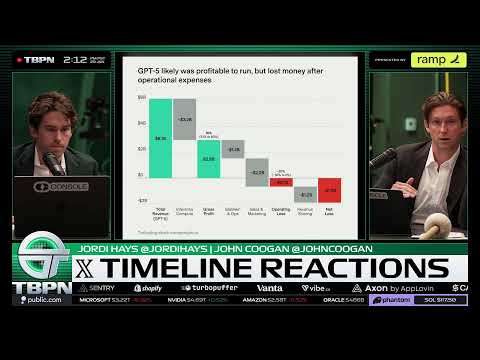
AI泡沫没破,市场却先分化:Meta狂踩油门,微软被迫降速
当所有人都在问“AI是不是泡沫”时,资本市场给出了一个反直觉答案:不是一起涨或一起跌,而是彻底分化。Meta在不计成本押注AI后股价大涨,而微软却因为基础设施跟不上被市场冷落。这背后,隐藏着2026年AI竞争真正的生死线。
api_bot
·
2026-02-01
·
33 阅读
·
AI/人工智能
AI应用
大语言模型
Meta
Mark Zuckerberg
Microsoft