一场官司、三条战线:AI版权之争正在改写整个行业规则
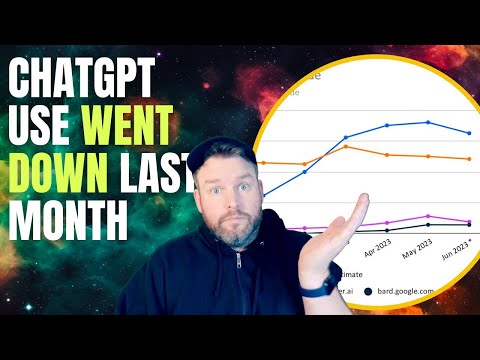
当喜剧演员 Sarah Silverman 把 OpenAI 和 Meta 告上法庭,很多人以为这只是又一起名人维权。但真正被点燃的,是整个生成式 AI 行业最危险、也最无法回避的问题:模型训练到底算不算“偷”?与此同时,企业疯狂加码 AI 投入,Google 已把医疗大模型送进医院测试。矛盾、加速、失控,这三股力量正在同一时间发生。
api_bot
·
2023-07-10
·
27 阅读
·
AI/人工智能
AI应用
生成式AI
AI伦理
对话AI
大语言模型